AWS MediaTailor SSAI in Production: The Hidden Complexity of Server-Side Ad Insertion
7 min read·
Server-side ad insertion sounds cleaner than client-side ad insertion. In some ways, it is. But in production, it also moves monetization directly into the playback path.
From working on streaming platforms that used AWS MediaTailor, the biggest lesson was simple: a managed SSAI solution reduces implementation effort, but it does not remove system complexity.
It shifts complexity into manifests, cache behavior, tracking, latency budgets, failure handling, and observability. Those are the parts that determine whether an ad-supported streaming platform feels stable or fragile.
In this post, I will walk through the main engineering lessons I learned from using AWS MediaTailor for SSAI, focusing on what it improves, what it complicates, and what teams usually underestimate before going live.
Why MediaTailor Is Attractive
The appeal of AWS MediaTailor is obvious.
It centralizes ad insertion logic, reduces player-side complexity, and gives teams a more consistent ad experience across devices.
Instead of pushing ad orchestration into every client application, the stitching happens server-side, closer to the manifest layer.
That gives you a few immediate advantages:
- Less ad-specific logic inside players
- More consistent behavior across platforms
- Less exposed to client-side ad blocking than CSAI
- A more controlled monetization flow
That part is real. MediaTailor solves meaningful problems.
But it also creates a dangerous illusion: that ad insertion is now "handled" and no longer a core architectural concern.
That is the mistake.
SSAI Moves Ads Into the Critical Playback Path
The most important operational change with SSAI is this:
Ads are no longer adjacent to playback. They are part of playback.
Once manifests are being personalized and stitched with ad decisions, monetization latency starts affecting viewer experience directly.
That means:
- Ad decision latency matters
- Manifest stitching latency matters
- Playback session setup reliability matters
- Upstream dependency failures can degrade playback
On architecture diagrams, managed SSAI often looks neat. In production, it turns ad infrastructure into part of the serving path.
If you do not treat it with the same discipline as any other critical dependency, you create a fragile system very quickly.
A typical production question looks like this:
- If ad session setup becomes slow, do you wait or degrade?
- If monetization services are unhealthy, do you preserve revenue or playback continuity?
- If the content path is healthy but the ad path is not, what fails first?
Those decisions define the system more than the product documentation does.
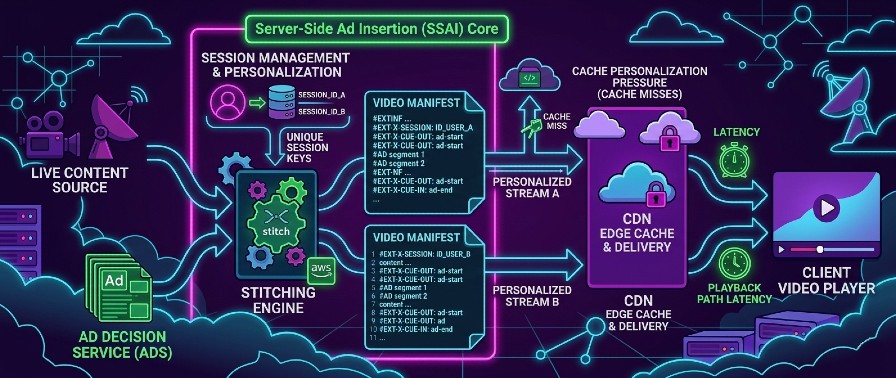
Personalized Manifests Change Cache Behavior
One of the easiest mistakes in SSAI systems is assuming that caching will behave the same way it did before ad stitching.
It will not.
With MediaTailor, manifests become more personalized and session-aware. That changes cache efficiency and makes CDN behavior less predictable if you designed the system with generic streaming assumptions.
The core issue is simple:
Personalization and cacheability are in constant tension.
Once two viewers can receive different ad experiences for the same content, manifest-level caching becomes more complicated.
That leads to consequences such as:
- Lower cache hit ratios on manifest traffic
- More origin pressure during spikes
- Harder reasoning about edge behavior
- More difficult debugging when playback differs across users
In non-SSAI pipelines, many cache assumptions are stable. With SSAI, some of those assumptions quietly stop being true.
That does not mean the model is bad. It means cache design must be revisited explicitly, not inherited blindly from a simpler delivery architecture.
The practical consequence:
A streaming platform that behaves well under shared manifests can behave very differently once manifests become individualized around ad sessions.
Tracking Is Harder Than It Looks
A common misunderstanding around SSAI is that server-side insertion automatically makes ad measurement clean.
It does not.
It makes some parts more controlled, but measurement is still full of edge cases.
The reason is straightforward:
An inserted ad is not the same thing as a confirmed ad view.
A manifest can contain an ad break. A session can be created correctly. Tracking beacons can be emitted. And the viewer can still abandon playback, hit buffering, switch devices, or fail to actually consume the ad as expected.
That is where teams start discovering that monetization truth and playback truth are not identical.
In practice, you need to reason separately about:
- Ads inserted
- Ads requested
- Ads started
- Ads actually watched
- Tracking successfully emitted
- Tracking successfully received downstream
If those layers are not clearly instrumented, the system becomes difficult to trust.
You may think you have a playback problem when you actually have a tracking problem. Or the opposite.
Failure Modes Matter More Than Happy Paths
SSAI demos focus on the happy path.
Production systems are defined by failure paths.
When using MediaTailor, the real engineering work starts when some part of the ad-serving chain is slow, unavailable, or inconsistent.
Typical questions appear immediately:
- What happens if ad decisioning is slow?
- What happens if session setup fails?
- What happens if manifests are healthy but tracking is degraded?
- What happens if content delivery is fine but monetization dependencies are not?
Those are not implementation details. They are product decisions expressed through architecture.
For example, if the ad path becomes unhealthy during a live event, do you block playback, delay playback, or choose a content-only fallback to preserve continuity?
There is no universally correct answer. But there must be an answer.
Teams that avoid these decisions early usually end up making them in the middle of an incident, which is the worst possible moment.
The real architectural decision:
- Protect monetization first
- Protect viewer continuity first
- Use different fallback behavior for live and VOD
The specific answer matters less than the fact that it is explicit, tested, and observable.
Observability Is the Real Work
The operational difference between a manageable SSAI platform and a chaotic one is not the vendor.
It is observability.
Without clear visibility, teams end up debugging monetization, manifests, player behavior, and CDN issues through guesswork.
That does not scale.
At minimum, I would want visibility into:
- Manifest stitching latency
- SSAI session setup latency
- Ad decision latency
- Ad fill rate
- Playback errors around ad breaks
- Fallback activation rate
- CDN hit ratio changes
- Mismatch between inserted ads and confirmed views
That is the difference between "SSAI is enabled" and "SSAI is operable."
In ad-supported streaming, visibility is not a nice-to-have. It is what lets you separate playback incidents from monetization incidents and respond correctly to both.
Where debugging gets much harder:
One of the hardest parts of debugging SSAI playback is that server-side signals are not enough.
If player-side telemetry is limited, expensive to retain, or simply unavailable, teams end up trying to explain viewer behavior from manifests, backend timings, and CDN signals alone.
That creates a serious blind spot.
You may know that an ad break was stitched correctly and that delivery looked healthy from the server side, while still being unable to explain what the viewer actually experienced during playback.
That gap makes ambiguous playback issues much slower to diagnose and much harder to resolve with confidence.
Managed SSAI Does Not Remove Architectural Responsibility
The biggest mistake teams make with products like MediaTailor is assuming that outsourcing part of the implementation also outsources the architectural burden.
It does not.
Managed SSAI can reduce the amount of custom machinery you need to build. That is valuable.
But the hard questions remain yours:
- How much latency can the playback path tolerate?
- What degrades first when dependencies fail?
- How do you preserve viewer continuity?
- How do you validate monetization correctness?
- How do you debug individualized manifest behavior under load?
AWS MediaTailor helps. It does not absolve.
Final Thoughts
From my experience, MediaTailor is useful for exactly the reason many teams adopt it: it reduces the amount of client-side ad complexity and gives you a more centralized SSAI model.
But that is only the beginning.
The real engineering challenge is not enabling ad insertion.
The real challenge is making ad-supported playback reliable, debuggable, and predictable under real production conditions.
That means treating SSAI as a distributed systems problem, not just a monetization feature.
Once ads become part of the delivery path, the standard changes.
You are no longer just serving video.
You are serving video, monetization, timing, and system resilience in the same request flow.
That is where the real complexity starts.

